
We are living in the age of Artificial Intelligence (AI), a transformative force reshaping nearly every industry—including the highly complex and data-intensive semiconductor manufacturing sector. Among the most promising technologies within AI is Machine Learning (ML), which enables the extraction of valuable insights from the vast quantities of data generated by semiconductor equipment and sensors.
However, deploying AI and ML to analyze equipment data is far from straightforward. The data’s complexity, variability, and volume introduce unique technical challenges that prevent many organizations from achieving production-ready AI integration. This article explores those challenges in depth, presents emerging strategies to overcome them, and introduces how the DEEP solution from PDF Solutions is purpose built to simplify and scale AI/ML deployment in equipment analytics.
To better understand the challenges of applying AI/ML to equipment data, it’s important to distinguish between supervised and unsupervised learning.
Supervised Learning
Supervised learning involves training a model on a labeled dataset, where each input is paired with a known output. This approach is highly effective for tasks such as classification and regression, where the model learns to predict outcomes based on historical examples. In manufacturing, supervised learning can be used to detect specific failure modes, predict tool wear, or classify product quality—provided that sufficient labeled data is available.
However, in real-world equipment data scenarios, obtaining labeled data is often impractical due to the challenges described below. These limitations make it difficult to apply supervised learning effectively.
Unsupervised Learning
Unsupervised learning, on the other hand, does not rely on labeled data. Instead, it identifies patterns, clusters, or anomalies within the data itself. This makes it particularly useful in industrial settings where labeled failure data is scarce. Techniques such as novelty detection, clustering, and autoencoders enable the detection of abnormal behavior without prior knowledge of specific failure modes.
Understanding the strengths and limitations of both approaches is crucial for designing robust AI/ML solutions in equipment analytics.
The Real-World Challenges of Equipment Data in AI/ML
The Scarcity of Labeled Data
One of the most significant hurdles in applying ML to equipment data is the lack of labeled datasets. Most equipment operates under normal conditions, and failure events—which are critical for supervised learning—occur infrequently. Even when failures do happen, they often go unlabeled, or the exact point of degradation is difficult to determine. For example, a motor operating a robot in a unit of semiconductor manufacturing equipment may operate for months without incident. When it finally fails, logs may only record the failure itself, not the weeks or months of subtle degradation leading up to it.
Labeling such events retrospectively is a difficult, time-consuming task that requires domain expertise. Only experienced engineers can reliably identify when meaningful changes in equipment behavior begin, and their time is limited and costly. Furthermore, human labeling introduces bias and uncertainty, especially in complex systems where multiple variables contribute to an outcome. As a result, labeled datasets are often small, imbalanced, or noisy—conditions that are far from ideal for training robust supervised models.
In a real example, a manufacturing company collected over 10 million sensor readings from a CNC milling machine. Among this vast dataset, only 37 samples were labeled as tool breakage events. Attempting to train a classifier with such a limited number of positive examples resulted in overfitting and false positives, ultimately eroding trust in the system.
The Complexity of the Machine Learning Workflow
Even when data is available, turning it into a working ML pipeline involves significant effort. Industrial environments typically generate high-dimensional, multi-rate, and noisy sensor data—torque, vibration, temperature, flow rates, current, and more—all recorded at different sampling rates and with varying latencies. Aligning, cleaning, normalizing, and extracting features from this data requires not only software expertise, but also deep knowledge of the underlying equipment and signal processing.
Consider a real-world example of predictive maintenance for robotic arms. Each arm may generate data from torque sensors, motor temperature sensors, cycle counters, and encoders. Preparing this data requires interpolation to align timestamps, filtering to reduce noise, and transformation, such as RMS (Root Mean Squared) or FFT (Fast Fourier Transform), to generate meaningful features. This is only the beginning. From there, a suitable ML model must be selected—such as an LSTM (Long Short-Term Memory) for time-series sample prediction or Isolation Forest for anomaly detection—trained on historical data and validated using carefully chosen metrics. Hyperparameters must be tuned, and models retrained periodically as wear patterns evolve or equipment is serviced.
Finally, deployment adds yet another layer of complexity. The model must be embedded into a live system, monitored for drift, and updated as new data becomes available. This process requires collaboration across teams: data engineers to handle analysis pipelines, data scientists to build models, equipment experts to interpret behavior, and IT teams to manage deployment infrastructure. For organizations without dedicated ML staff, the barrier to entry is substantial.
The fact that no internet connection is allowed from semiconductor facilities makes the matter even more challenging, since the ML solution cannot run on a more powerful cloud system. The solution should run on an equipment PC that usually has limited computing power.
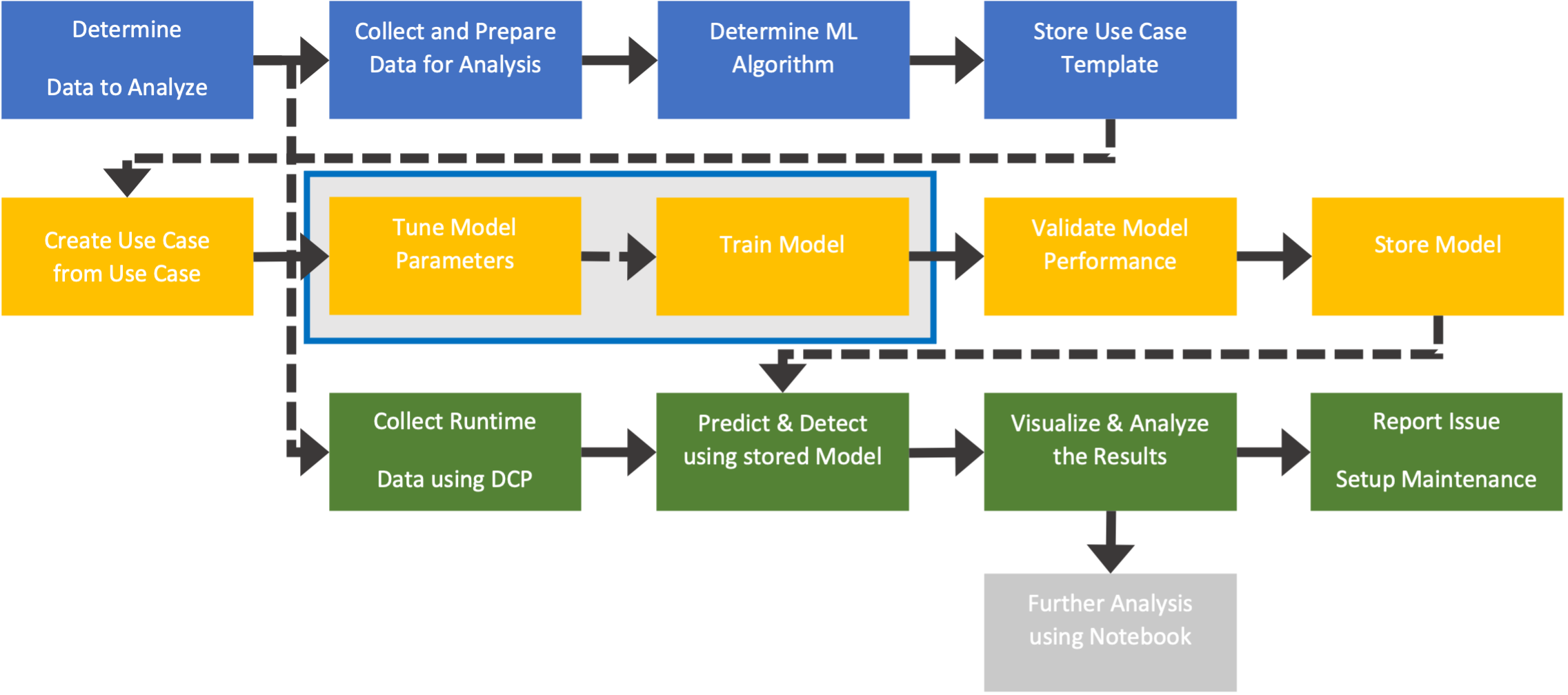
Workflow to apply ML to equipment data analysis
Regardless of the type of equipment type or process, the following steps are needed in most cases. Whether there is an underlying solution platform or the users need to build all solutions from scratch, the ML development process takes time and resources, which increases the time-to-market (or time to production use) for the system. The total cost of ownership will also be higher if all solutions are maintained in-house.
Technical Strategies to Address the Challenges
Despite these difficulties, many promising techniques have emerged to bridge the gap between raw equipment data and usable machine learning models.
Novelty Detection
Novelty detection is an unsupervised learning technique that identifies deviations from normal behavior without requiring labeled fault data. The system is trained exclusively on examples of normal operation and learns to recognize the statistical boundaries of “normal.” During inference, any input that falls outside these boundaries is flagged as anomalous.
This method is ideal for predictive maintenance and early fault detection scenarios where labeled fault data is sparse or nonexistent. It is particularly useful in high-uptime environments like semiconductor fabs, where failures are rare but costly.
Synthetic Data Generation
Synthetic data generation addresses the scarcity of labeled fault data by simulating failure scenarios and edge conditions. This is especially useful in controlled environments where generating real failures is costly or impractical. By combining physics-based simulations, generative models, and/or domain-specific rules, engineers can augment their datasets to improve model robustness and reduce overfitting.
For example, in the previous example of having only 37 failure data points in 10 million sensor readings, the 37 data points can be used as seeds to synthesize abnormal data patterns or simulating gradual wear, helping to train models to recognize early signs of failure that may otherwise go unrepresented in historical logs.
Semi-Supervised GANs
Generative Adversarial Networks (GANs) can be extended into a semi-supervised learning framework to improve classification performance with limited labeled data. In this approach, a GAN is trained to both generate realistic equipment behavior and classify data samples, using a small set of labeled examples and a large pool of unlabeled data.
The generator learns to produce plausible sensor data, while the discriminator is trained to both distinguish real vs. synthetic samples and classify inputs. This dual-role training process allows the model to generalize well, even when high-quality labels are sparse.
Semi-supervised GANs are especially promising for complex equipment behavior modeling, where subtle deviations in multivariate signals can signal degradation, but labeled data is insufficient for fully supervised learning.
Autoencoders for Feature Extraction
Autoencoders are neural networks that learn to compress and reconstruct input data. Trained on normal data, they produce low reconstruction errors for similar inputs but fail to accurately reproduce anomalous data. This discrepancy can be used as an anomaly score. Autoencoders are well-suited for modeling high-dimensional sensor data and time-series streams, often serving as powerful unsupervised feature extractors.
Once trained, they provide a compressed latent representation of input data, useful for visualization, clustering, or as input to secondary models. Autoencoders also integrate well with other techniques such as novelty detection and dimensionality reduction.
Two-Phase Novelty Detection
This structured approach separates model development into two phases. During the learning phase, a model (typically an autoencoder) is trained on normal data and statistical thresholds are established using the reconstruction error. In the testing phase, incoming data is evaluated against these thresholds to detect outliers. This method provides a quantifiable and maintainable approach to anomaly detection, and it works well in production environments where retraining is costly or impractical.
How DEEP Simplifies AI/ML Deployment for Equipment Analytics
DEEP, a solution developed by PDF Solutions, is designed specifically to overcome the challenges of applying AI/ML to equipment data. It combines robust ML infrastructure with intuitive user interfaces to support the entire analytics lifecycle—from data ingestion to real-time inference.
Automation of the ML Workflow
DEEP automates many of the tedious and error-prone steps in the ML pipeline. This includes data collection from equipment, preprocessing and alignment of time-series data, and the setup of ML workflows through guided templates. Instead of requiring users to manually design and train models, DEEP offers a library of pre-configured use cases that can be adapted to specific equipment and sensor patterns.
The following diagram shows how DEEP provides help throughout the whole ML process.

Guided Templates and Use Case Libraries
The solution provides a growing collection of model templates, curated by DEEP data scientists, which are tailored to common equipment behaviors. For instance, templates may target specific relationships such as heater power versus temperature or pump flow rate versus pressure. These templates allow users—even those without ML backgrounds—to create, train, and validate models using built-in guidance and domain best practices.
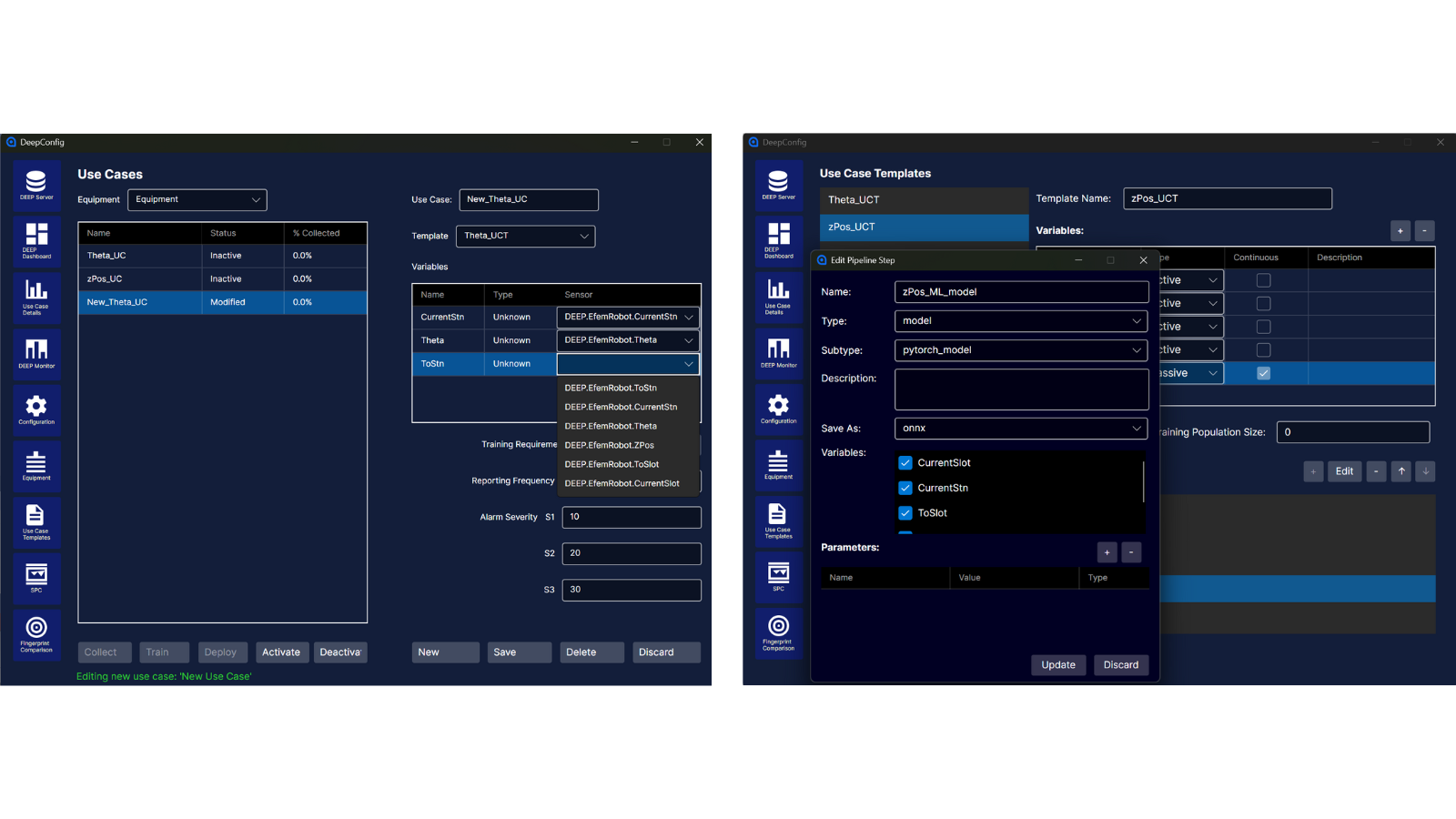
Creating use case by copying a use case template
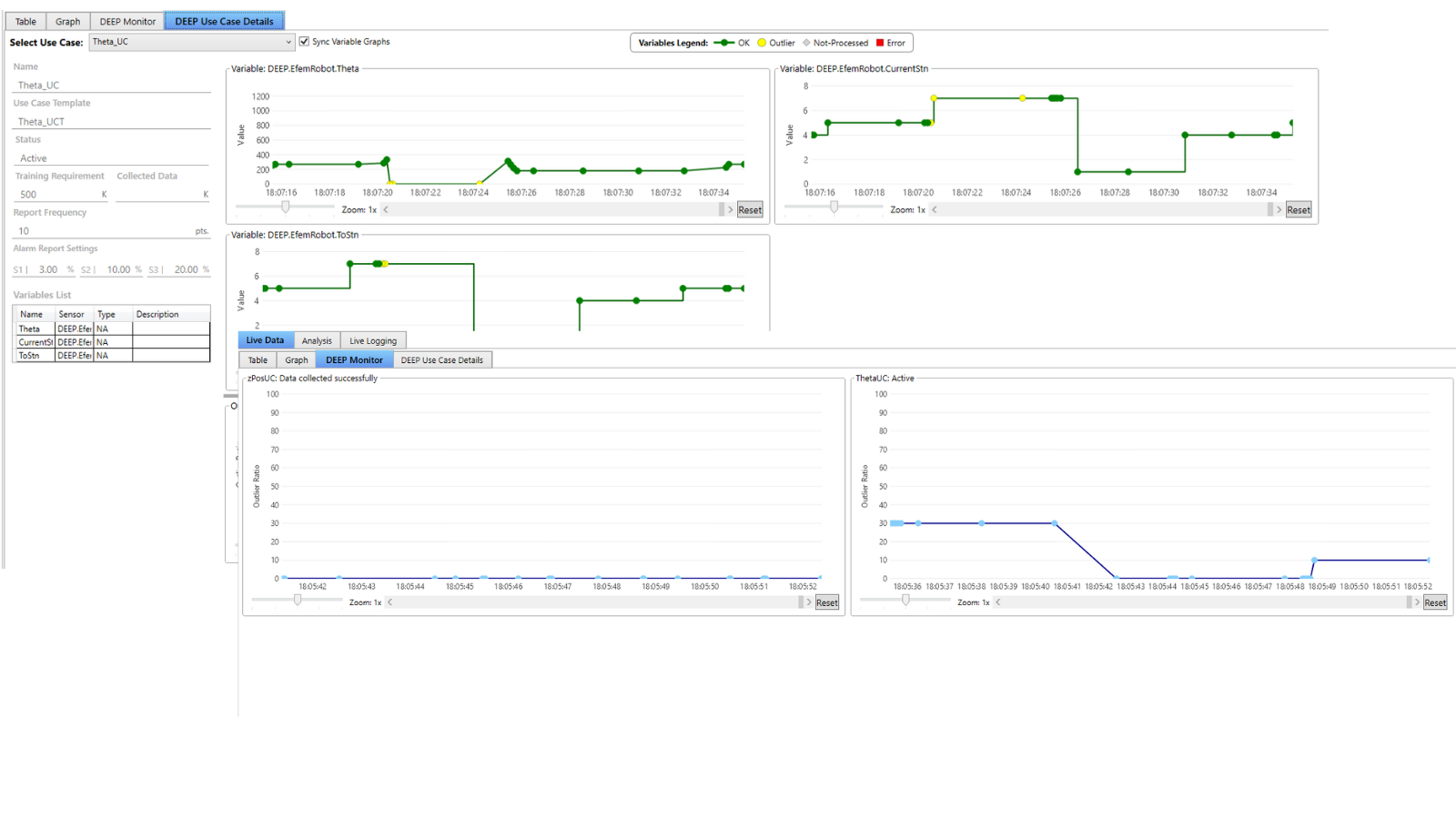
Dimensionality Reduction and Time-Series Alignment
To handle the complexity of sensor data, DEEP supports dimensionality reduction techniques such as PCA, t-SNE, and UMAP (Principal Component Analysis, t-distributed Stochastic Neighbor Embedding, and Uniform Manifold Approximation and Projection). These methods help uncover structure in high-dimensional data and facilitate visualization and clustering. DEEP also supports time-series alignment through resampling and efficient indexing, which ensures consistency across multi-rate sensor streams.
Continuous Re-Learning and Model Adaptation
Equipment behavior changes over time due to wear, maintenance, or process drift. DEEP includes mechanisms for automated retraining and model versioning, allowing deployed systems to adapt without manual intervention. This enables sustained model accuracy and robustness in dynamic environments.
Data Security and Governance
Data privacy is a priority in any production environment. DEEP uses gRPC (an open-source framework for Remote Procedure Calls) with encryption to securely transmit data, and access control is enforced through a permission-based system. This ensures that sensitive equipment data remains protected and compliant with customer policies.
Final Thoughts
Integrating AI/ML with equipment data in semiconductor and advanced manufacturing is a high-impact opportunity—but it is also technically demanding. From the scarcity of labeled data to the complexity of real-time deployment, the barriers are real. Yet with the right tools and strategies, they are also solvable.
Cimetrix DEEP bridges the gap by combining automation, expert-curated templates, advanced analytics techniques, and secure deployment into a unified solution. By lowering the barrier to entry, DEEP empowers engineering teams, data scientists, and manufacturers to harness the power of AI—turning raw equipment data into actionable insights and competitive advantage.